
An Analysis of the Prevalence of US Events on Reddit
Introduction
Reddit is a social media site that is based in the US, but widely used internationally. Users can submit content such as text posts, images, and links. To express how much users like or dislike the content, they can either upvote or downvote the posts. There exists smaller communities called subreddits that allow users to view and post content for specific topics such as news, politics, video games, and lifestyle. Users can interact with content in a variety of ways, for instance by commenting to posts, gifting rewards to submissions or comments, or simply by upvoting or downvoting comments.
The year 2020 has been a turbulent one for many people worldwide with events such as the Coronavirus pandemic, the U.S. election, riots, and countless other events. As a result, there are more and more submissions with links to news articles that describe these events. With many of these events occurring within the United States, many users and subreddits have grown tired of hearing solely about what is happening in the U.S. and have opted to try to filter posts that were about U.S. events or politics.
In this tutorial, our goal is to verify whether the sentiment that U.S. events have become more prevalent over the year 2020. We will then look past the year 2020, and look at the past 11 years to see if there are any trends with how prevalence of the US.
We will use PushShift, a Reddit API that allows us to search Reddit comments, and various other Python modules in this tutorial.
Install the dependencies needed for this project
pip install nltk
# In order to get make requests to get the data
import requests
import json
# To work with the data we are going to store it in a dataframe
import pandas as pd
import numpy as np
from datetime import datetime
import time
# Visualization
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from matplotlib.dates import DateFormatter
# Machine Learning and Statistics
import nltk
from nltk.tokenize import word_tokenize
# Download additional resources
nltk.download('punkt')
from collections import Counter
# For calculating IDF
import math
from heapq import nlargest
# For regression
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import LinearRegression
# For model evaluation
from sklearn.metrics import r2_score
The Difficulties Getting Data from Reddit
Before diving into the data collection, it is important to learn more about the choice to use PushShift for this project, and the challenges that come with querying Reddit for data.
The main difficulty that comes with getting data from Reddit is that users are unable to query Reddit for date-specific results, as we are trying to do in this project. For example, if someone was interested in all submissions from the year 2015, Reddit offers no way to specifically get those submissions. While we would be able to search using the typical Reddit timeframe filters such as last day, last month, last year, and all time, this method of querying becomes increasingly difficult as the timeframe the posts were submitted in becomes further away from present day. For example, if we were to attempt to get all the 2015 posts using this method, we would have to use the 'from all time' filter and manually go through each post and determine whether they were in the specified timeframe. This involves working through an extremely large number of posts.
It is because of this that we turn to PushShift to get data.
About PushShift, its Advantages and Shortcomings
As described previously, we are unable to use Reddit's existing API for this project since we need to get submissions within a specific timeframe. However, PushShift allows us to get around this problem.
PushShift copies submissions into their database at the time they are posted, and updates these submissions in their database with the most up to date version of comments and upvotes in regularly timed intervals. By having what is essentially a deep copy of the Reddit submissions and comments, one can use their API to query their database for up to 100 posts at a time, and search for a variety of submission parameters, such as timeframe, score, and etc. More specifics can be learned about the PushShift API from the following links at their Reddit, Github, and Site respectively.
- https://www.reddit.com/r/pushshift/comments/bcxguf/new_to_pushshift_read_this_faq/
- https://github.com/pushshift/api
- https://pushshift.io/
However, unfortunately this is not a perfect solution to the problem. Since PushShift has to maintain their own database apart from Reddit, they do not always have the most up to date information regarding submissions from Reddit. This means that data we get back may not always be up to date. Additionally, from analysis, there are some posts that should be among the top submissions in a given year, but are completely missing when a request is sent for the top submissions, a process which will be described in the next sections. From research, it appears that these posts are missing simply because these posts have not been added to the PushShift dataset yet or have not had their upvotes updated yet, which makes sense since there is an ever increasing amount of posts that must be read into the dataset and updated as time goes on.
While it is unfortunate, since the likelihood of a post being not included in a request for top submissions seems to be tied to the random workings of PushShift's dataset and how it updates, and not properties of the submissions like upvotes, we will label these posts as Missing Completely at Random. This means that when we get the top 1000 posts, we will actually be looking at a subset of the top posts in a given year. While any conclusions we draw will not be as strong as if we had the true data, having a subset of fairly accurate data still will at least be representative of the true trends of Reddit.
Data Preparation
Data Collection
In order to get the data we need for this project, we need to query Pushshift in order to get the data required. Let's first make some functions. Let's make one that will get the data by querying Pushshift and get the top 100 posts from a subreddit.
When we send a request to the PushShift API, we get a list of dictionary objects that represent a submission. The size of this list, along with what fields are included in the dictionary, are dependent on the request we send PushShift. To query pushshift, we essentially have to send a GET request to a link, which primarily involves the building of the URL. Before starting, it would be helpful to have these two links read or pulled up:
- https://github.com/pushshift/api#searching-submissions
- https://github.com/pushshift/api#search-parameters-for-submissions
To start, we are going to specify the endpoint, or base URL we will be sending the query to. In the case of submissions this will be: https://api.pushshift.io/reddit/search/submission/
To add additional parameters to search for, we will need to add an additional "?" to the end of the url followed by the parameter name, an equal sign, and finally the value of the parameter. If there are multiple parameters, there will need to be an "&" separating parameters and thier values. An example of this is shown below, with place_holder values being in "<>"
An example of searching submissions with "Trump" in the title after 2015 would be:
For the data we want, we would need to know the title, the number of upvotes, any flairs (optional text labels), what subreddit the post belongs to, and when it was created. It might also be useful to collect the link to the post and how many comments the post has. We can set this by using the "fields" parameter and setting it equal to a concatenated and comma_separated string in containing the fields below. This will prevent us from getting extranous data back from requests.
- created_utc - when the post was created
- full_link - the link to the actual post on Reddit
- num_comments - the number of comments on the post
- score - the number of upvotes the submission has
- subreddit - the name of the subreddit the submission belongs to
- title - the text title of the submission
- link_flair_text - the text of the flair assigned to the post. Flairs are essentially subcategories submissions can optionally be assigned to.
Unfortunately, it appears that there is not a comprehensive list of fields. To see what ones you want, get a request without the fields parameter and then build a string in a similar way that I do below. More information here: https://github.com/pushshift/api#using-the-fields-parameter
Additionally, we need to include the parameters before and after to get submissions from a specific timeframe. By setting the "sort_type" parameter to score, we are receiving the highest upvoted score. By including the "score=<" we can get all posts below a certain score, which will be used in the next part. Including the "size" parameter will allow us to specify how many submissions we get back, up to 100. Finally, we will need to include the "subreddit" parameter to search specific parameters.
I also included the "title" parameter for general use requesting.
The process of building the string given specific parameters is seen below, as well as an example of some output.
# Lets build the url which we will send requests to in order to get posts within a certain timeframe.
# For the sake of this project, we are interested in the top posts, but you can also change the 'sort_type' to
# get posts based on the time they were created ('created_utc'), the number of comments the submission has ('num_comments'),
# or mumber of upvotes
def get_pushshift_data(term, start, end, subreddit, num_posts, score_threshold):
# Limit the data fields we get back. We don't need everything!
# It'd be useful to collect the flair as a potential y for machine learning predictions we do later
f = ('created_utc,' +
'full_link,' +
'num_comments,' +
'score,' +
'subreddit,' +
'title,' +
'link_flair_text'
)
# Build the url which will send the data we are looking for
url = ('https://api.pushshift.io/reddit/search/submission?' +
'title=' + str(term) +
'&after=' + str(start) +
'&before=' + str(end) +
'&size=' + str(num_posts) +
'&fields=' + f +
'&score=<' + str(score_threshold) +
'&sort_type=score' +
'&subreddit=' + str(subreddit))
# We are ensuring we are getting the highest posts with sort
# Get the data, sleep so the successive calls do not trigger a 429 response
time.sleep(1)
r = requests.get(url)
# Convert the request into a list of dict objects
d = json.loads(r.text)
# Return a list of dictionaries for the submissions
return d['data']
# Lets test it by getting three posts from the world news subreddit in the year 2020 that contains Trump
ex = get_pushshift_data('Trump', '2020-01-01', '2020-12-31', 'worldnews', 3, 1000000)
ex
Data Curation¶
Now that we pretty general method of querying PushShift RESTful API, let's now get the top 1000 posts in a year and put it in a dataframe
With there being a limit of 100 per query, if we want to get more than 100 submissions per year, we are going to have to have some workaround if we want to have more than 100 submissions per year.
One approach would be to get 100 submissions for each of the 12 months, and then aggregate over them. However, this method would limit the type of exploratory analysis we could do. For example, if we wanted to see the distribution of month vs. upvotes, we would not see the whole picture since the true distribution of the most popular posts may only be in a few select months, rather than all.
What we are going to do instead is sample the whole year but each time keep track of the score. After each query, we will search for all posts below the lowest score from the last batch that was returned. This is why we included the "score=<" field in our function.
At the end of this iterative process, we will have a list of 1000 dictionary objects that can trivially be transformed into a Pandas DataFrame. An example of this is output at the bottom of the next code cell, for getting the top 1000 posts of the worldnews Reddit for the year 2020.
# num_top is expected to be a multiple of 100
def get_top_submissions_for_year(subreddit, term, year, num_top):
return_lst = []
num_iter = num_top//100
# Preset the max score to 1 million and lower it based on the lowest submission score
max_score = 1000000
start_date = str(year) + '-01-01'
end_date = str(year) + '-12-31'
for i in range(num_iter):
return_lst = return_lst + get_pushshift_data(term, start_date, end_date, subreddit, 100, max_score)
max_score = return_lst[-1]['score']
return pd.DataFrame(return_lst)
# Example of getting the top 1000 entries from worldnews
df = get_top_submissions_for_year('worldnews', '', 2020, 1000)
df
Data Tidying
Now let's make the DataFrame more tidy, as its current layout is a bit unintuitive.
Let's swap the order of columns around and replace the created_utc column with a datetime object to improve what we can get from looking at the table. Having a datetime object in the column is also much easier for plotting, which we will do in the Exploratory Data Analysis section.
While the full_link is useful for troubleshooting and confirming, it probably also will not be too useful in our analysis.
Finally, let's rename the column titles to be a bit more descriptive.
def tidy_df(df):
df = df.copy()
date_time_lst = [datetime.utcfromtimestamp(x) for x in df['created_utc']]
df['date'] = date_time_lst
df = df.drop(['created_utc', 'full_link'], axis=1)
if 'link_flair_text' not in df.columns:
df['link_flair_text'] = np.nan
df = df[['title','score','date','link_flair_text','num_comments','subreddit']]
df = df.rename(columns={'title':'submission_name','link_flair_text':'flair'})
return df
# Example tidying the df we got from the last step
d = tidy_df(df)
d
Getting all the Data
Now that we have all these functions in place, let's get all the data that we will need.
We will define a function that will combine the functions from all the previous steps and return a single DataFrame ready for work. Essentially, we just need to call tidy_df() on the dataframe we get back from get_top_submissions_for_year(). The parameters needed for this are the subreddit we are interested in searching (subreddit), the term in the title (term), if any, the year we are interested in (year) , and finally the number of top posts we want (num_top), which must be a multiple of 100.
Since we have to include a wait so that we do not get a 429 Response (Too Many Requests), it would be much easier, especially in the future to write all this data to a csv so we can read it later. Pandas has a method for doing this given a DataFrame, making this step extremely easy.
The only other thing we are going to do, is just repeat the above function for 11 different years, and store the resulting DataFrame in a .csv in our working directory. Let's call this function get_data_10_years(), taking the string name of a subreddit as a parameter.
Finally, let's only call this function if necessary, as the waiting to avoid a 429 error is extensive.
def get_data(subreddit, term, year, num_top):
return tidy_df(get_top_submissions_for_year(subreddit, term, year, num_top))
# Function to get all world news data
def get_data_10_years(subreddit):
year_lst = [2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020]
return_lst = []
for year in year_lst:
df = get_data(subreddit, '', year, 1000)
return_lst.append(df)
df.to_csv(subreddit + '_' + str(year) + '.csv', index = False, header = True)
return return_lst
# Keep a boolean value to determine if we need to re-collect data
fresh_run = False
if (fresh_run):
worldnews_lst = get_data_10_years('worldnews')
Exploratory Data Analysis
Now that we have the data, we can do some exploratory data analysis. For the of reproducability, I have stored the dataframes that I will using in my analysis in this zip so that they can be downloaded if anything were to happen to either the Reddit API or the PushShift API.
Click here to download the data in a .zip file.
Unfortunately, we will have to reconvert the date column into a datetime object when we read it from a csv. Luckily, Pandas has a function that will do this for us without much work because of the format the datetime object was saved as in the csv.
To start, let's load the .csv files we created in the last part into variables we will perform analysis on.
def convert_str_datetime(df):
df['date'] = pd.to_datetime(df['date'])
return df
# My csv files are in a directory called data
worldnews_2020 = convert_str_datetime(pd.read_csv('data/worldnews_2020.csv'))
worldnews_2019 = convert_str_datetime(pd.read_csv('data/worldnews_2019.csv'))
worldnews_2018 = convert_str_datetime(pd.read_csv('data/worldnews_2018.csv'))
worldnews_2017 = convert_str_datetime(pd.read_csv('data/worldnews_2017.csv'))
worldnews_2016 = convert_str_datetime(pd.read_csv('data/worldnews_2016.csv'))
worldnews_2015 = convert_str_datetime(pd.read_csv('data/worldnews_2015.csv'))
worldnews_2014 = convert_str_datetime(pd.read_csv('data/worldnews_2014.csv'))
worldnews_2013 = convert_str_datetime(pd.read_csv('data/worldnews_2013.csv'))
worldnews_2012 = convert_str_datetime(pd.read_csv('data/worldnews_2012.csv'))
worldnews_2011 = convert_str_datetime(pd.read_csv('data/worldnews_2011.csv'))
worldnews_2010 = convert_str_datetime(pd.read_csv('data/worldnews_2010.csv'))
df_lst = [worldnews_2010, worldnews_2011, worldnews_2012, worldnews_2013, worldnews_2014, worldnews_2015, worldnews_2016,
worldnews_2017, worldnews_2018, worldnews_2019, worldnews_2020]
To begin, let's look at the distribution of upvotes vs. time for the year 2020. There were two notable events in the US that garnered a lot of international attention, those being:
1) Initial COVID outbreaks in the US in March/April
2) BLM Protests that occurred after the death of George Floyd in the Summer of 2020
By visualizing this distribution, we will be able to see if the US does get more popular posts during these months, and if so then this might be a good indicator for whether the US was more prevalent in news during the year 2020. The US had many different issues come up that in the past year, and if there is a considerable amount of traffic with two events, then there might be even more in total.
plot = worldnews_2020.plot.scatter(x='date', y='score', c='DarkBlue', figsize=(15,10), fontsize = 10)
plot.set_title('Date vs. Upvote Score for Submissions to Worldnews Subreddit in 2020', fontsize = 15)
plot.set_ylabel('Number of Upvotes', fontsize = 15)
plot.set_xlabel('Date', fontsize = 15)
# Format date
date_formatter = DateFormatter('%m-%y')
plot.xaxis.set_major_formatter(date_formatter)
# Update ticks
plot.xaxis.set_major_locator(mdates.MonthLocator(interval=1))

Looking at the scatter plot above, it would appear that our prediction may at least be partially true. Let's investigate this further by looking at making simple classifiers for the title to see whether they fit in our category.
To do this, let's just make a list of terms that may be in the title of a post about that topic. If any term is within that title, we would keep it and display its score on the scatterplot.
For the first event on the Coronavirus, some terms that might be a good indicator that the submission is about would just be if it contained the different variations that the modern Coronavirus has been referred to, such as:
- covid
- covid-19
- corona
- coronavirus
We can use the (?i) marker when defining our term list since there may be many cases of different capitalization. Since the words do not mean drastically different things depending on capitalization, we should ignore. However, we should not do the same thing in the case of "us" and "US"
Additionally, we can use flairs to determine the content. The worldnews subreddit has used the "COVID-19" flair to denote submissions as related to COVID, and we can use this to also determine whether a submission is about the Coronavirus.
Finally, in the following examples, we will also print out a few of the titles to see what kind of content our classifier picked out.
terms = '(?i)covid|covid-19|corona|coronavirus'
lst_1 = worldnews_2020['submission_name'].str.contains(terms).tolist()
lst_2 = (worldnews_2020['flair'] == 'COVID-19').tolist()
filter_lst = []
for i in range(len(lst_1)):
filter_lst.append(lst_1[i] or lst_2[i])
filter_lst = pd.Series(filter_lst)
covid_df = worldnews_2020[filter_lst]
print('Submissions that match:')
print(len(covid_df))
plot = covid_df.plot.scatter(x='date', y='score', c='DarkBlue', figsize=(15,10), fontsize = 10)
plot.set_title('Date vs. Upvote Score for Submissions to Worldnews Subreddit in 2020 (Coronavirus)', fontsize = 15)
plot.set_ylabel('Number of Upvotes', fontsize = 15)
plot.set_xlabel('Date', fontsize = 15)
# Format date
date_formatter = DateFormatter('%m-%y')
plot.xaxis.set_major_formatter(date_formatter)
# Update ticks
plot.xaxis.set_major_locator(mdates.MonthLocator(interval=1))
temp = covid_df.copy()
with pd.option_context('display.max_colwidth', None):
display(temp.drop(['flair','num_comments','subreddit'], axis=1).head(15))

With the scatter plot above, it seems that out prediction of a surge of posts about the Coronavirus when it hit the US in Spring may be true! To look further, let's make another 'classifier' to filter out posts further to see what proportion of these posts about Coronavirus may also be related to the US.
For the terms that may indicate whether or not whether a post is about the US, let's use (case specific):
- US
- United States
- U.S.
us_terms = 'US|United States|U.S.'
filter_lst = covid_df['submission_name'].str.contains(us_terms).tolist()
covid_us_df = covid_df[filter_lst]
print('Submissions that match:')
print(len(covid_us_df))
plot = covid_us_df.plot.scatter(x='date', y='score', c='DarkBlue', figsize=(15,10), fontsize = 10)
plot.set_title('Date vs. Upvote Score for Submissions to Worldnews Subreddit in 2020 (Coronavirus and US)', fontsize = 15)
plot.set_ylabel('Number of Upvotes', fontsize = 15)
plot.set_xlabel('Date', fontsize = 15)
# Format date
date_formatter = DateFormatter('%m-%y')
plot.xaxis.set_major_formatter(date_formatter)
# Update ticks
plot.xaxis.set_major_locator(mdates.MonthLocator(interval=1))

By filtering the submissions further, we see that top submissions about the Coronavirus and the US are either centered around April, or spread out in the summer. It's worth noting that of the original 253 coronavirus submissions in the year, 27 seem to about about the US.
Let's take one further look at how many fall within April and how many do not, in addition to looking at the top few posts.
temp = covid_us_df.copy()
with pd.option_context('display.max_colwidth', None):
display(temp.drop(['flair','num_comments','subreddit'], axis=1).head(15))
# Now lets see how many of these 27 posts were in April
count = 0
may_datetime = datetime.strptime('2020-05-01', '%Y-%m-%d')
for d in temp['date'].to_list():
if d < may_datetime:
count = count + 1
print('Total submissions in April: ' + str(count))
Looking at this, there are about 10 submissions clustered together in April, and the remaining 17 were spread over the remainder of the year.
Currently, these statistics are not too telling of a US prevalence on the worldnews subreddit. Only about 10% of all top submissions about the Coronavirus are about the US. Let's keep looking with the Black Lives Matter Protests in the summer of 2020.
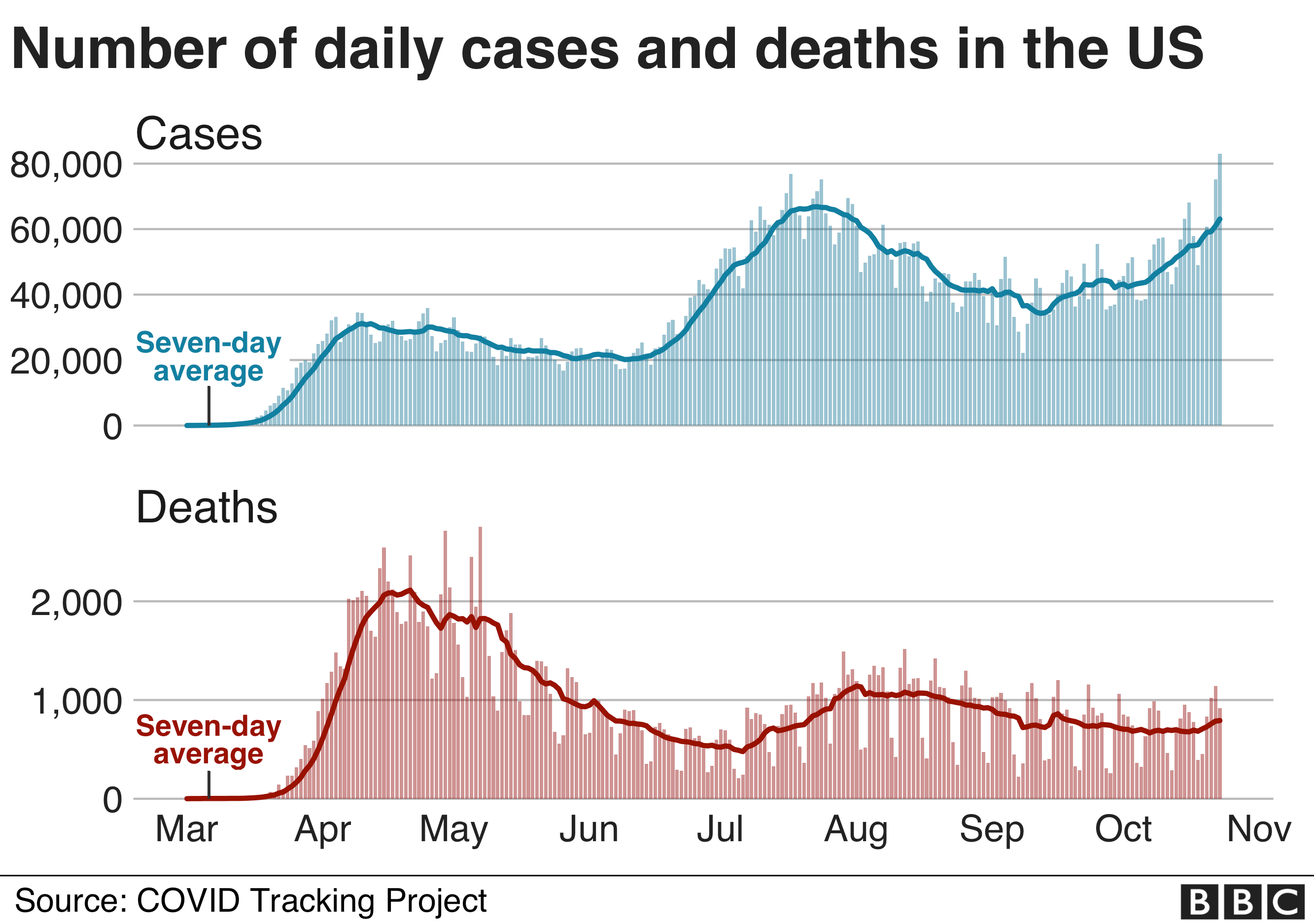
However, it is important to note that these results make sense for the most part! Even though our classifier was not able to get a large proportion of submissions to be about the US and the Coronavirus, these the times that were centers of the distribution seem to align with surges in the Coronavirus. As we see centers mid April and mid July, we also see a surge in daily cases. See the image below, courtesy of BBC.(https://www.bbc.com/news/world-us-canada-54670386)
Let's repeat the process that we did when searching for submissions about the Coronavirus and create a list of terms to search for submissions relevant to the Black Lives Matter protests. Some terms that might be a good hit are (non-case sensitive):
- BLM
- riot
- protest
- floyd
- Black Lives Matter
- defund
- rioters
Theses terms were chosen because the were some of the most popular words used to describe the protests that went on at the time. I also included 'defund' because of the popular saying of "defund the police" that was going on during this time.
Let's also see the top 15 submission's titles, to get a gauge on whether the most popular posts are specific to the US, or just protests in general
terms = '(?i)blm|riot|protest|floyd|black lives matter|defund|rioters'
protest_df = worldnews_2020[worldnews_2020['submission_name'].str.contains(terms)]
print('Submissions that match:')
print(len(protest_df))
plot = protest_df.plot.scatter(x='date', y='score', c='DarkBlue', figsize=(15,10), fontsize = 10)
plot.set_title('Date vs. Upvote Score for Submissions to Worldnews Subreddit in 2020 (Protests)', fontsize = 15)
plot.set_ylabel('Number of Upvotes', fontsize = 15)
plot.set_xlabel('Date', fontsize = 15)
# Format date
date_formatter = DateFormatter('%m-%y')
plot.xaxis.set_major_formatter(date_formatter)
# Update ticks
plot.xaxis.set_major_locator(mdates.MonthLocator(interval=1))
temp = protest_df.copy()
with pd.option_context('display.max_colwidth', None):
display(temp.drop(['flair','num_comments','subreddit'], axis=1).head(15))

Looking at the scatterplot, it appears that there is a center for protests around the predicted timeframe of the summer of 2020! We see in total, there are 54 submissions that match! Additionally, looking at the top 5 submissions it would seem almost all are about the US. It's important to note that during this time, the protests in the US also sparked protests worldwide. This is seen in the final submission printed above, where the story two Canadian police seems to have been influenced by events in the US. This is important to note, as events in the US may have influenced events in other countries, making it hard to determine exactly how much the US is prevalent in news if they are not explicitly mentioned in the title.
Let's try to use a similar technique with the US classifier and see if we can see a center in mid June by filtering the protest submissions further.
Let's currently just reuse the same term list as before, which was just different case sensitive variations of the "United States"
us_terms = 'US|United States|U.S.'
filter_lst = protest_df['submission_name'].str.contains(us_terms).tolist()
protest_us_df = protest_df[filter_lst]
print('Submissions that match:')
print(len(protest_us_df))
plot = protest_us_df.plot.scatter(x='date', y='score', c='DarkBlue', figsize=(15,10), fontsize = 10)
plot.set_title('Date vs. Upvote Score for Submissions to Worldnews Subreddit in 2020 (Protests and US)', fontsize = 15)
plot.set_ylabel('Number of Upvotes', fontsize = 15)
plot.set_xlabel('Date', fontsize = 15)
# Format date
date_formatter = DateFormatter('%m-%y')
plot.xaxis.set_major_formatter(date_formatter)
# Update ticks
plot.xaxis.set_major_locator(mdates.MonthLocator(interval=1))
temp = protest_us_df.copy()
with pd.option_context('display.max_colwidth', None):
display(temp.drop(['flair','num_comments','subreddit'], axis=1).head(15))

Once again we see that the US is explicitly mentioned in 20% of submissions about protests. However, it could be argued that about 90% of these articles had the US involved at least indirectly, as many protests broke out in countries such as France in response to the events that were occuring in the US. Finally, it is a bit unfair to limit to further limit the scope to titles that include both sets of terms since terms like "Black Lives Matter" already have origins and ties to the US.
If we were to count the 27 submissions that were about the US and Coronavirus and about 90% of the 54 submissions about rioting (Since it is arguable that most posts about protests had ties to the US protests), then about 75 out of the top 1000 posts, then the US took up 7.5% of the most popular submissions with just two main events that occurred in 2020.
If only two events led the US to take up almost 10% of the top submissions, then it is very likely that including all the events will lead the US to have an even higher percentage of the top posts for the year 2020. In the next section, we will attempt to predict this amount by refining our US classifer to see how much the US was involved in the top 1000 submissions of 2020, and using machine learning techniques, specifically linear regression, to predict whether this percentage per year has been increasing over the past 11 years.
Classification and Prediction
To begin, we are going to refine our basic US classifier. Intuitively, there are more terms other than "US", "U.S." and "United States" that signify whether a submission pertains to the US. A trivial example is "Trump", the current president of the United States.
To do this, we will fit a logistic regression to the titles of the top 100 submissions of 2020 and use it to see if there are any more terms that we should add to our naive US classifier. This will involve converting the titles of submissions to a bag of words representation, where each submission title is a vector of word frequencies. These will be our X's, or input data that we will use to predict the y, or expected result. After fitting the model, we will get the logistic model's highest coefficients as a gauge for the most impactful words for classifying submissions about the US.
To do this, we are using the Natural Language Toolkit in Python to tokenize words. A trivial example is displayed below where we keep all alphanumeric words.
s = "This is a test setence! It will include the 320 in CMSC 320!"
words = nltk.word_tokenize(s)
new_list = list()
words = [new_list.append(word.lower()) for word in words if word.isalnum()]
print(new_list)
First let's make a dictionary that keep tracks of the frequency of each word in every submission title for the top 100 submissions of 2020. We will do this by first iterating over every title, and then iterating over every alphanumeric word in the title, and either adding it to our dictionary or incrementing its value in our dictionary.
Let's also display the top 10 most commonly used words using the Counter module in Python, which can take a dictionary as a paramter and return the n highest values using the most_common() function.
# Get the submissions using our 'naive' US classifier
data = worldnews_2020.head(100)
# Create a dictionary to keep track of the frequency
freq = dict()
titles = data['submission_name'].to_list()
for title in titles:
for word in nltk.word_tokenize(title):
if word.isalnum():
if word in freq.keys():
freq[word] = freq[word] + 1
else:
freq[word] = 1
# Display the results
c = Counter(freq)
c.most_common(10)
As expected, articles dominate the most frequently used words. To circumvent this issue and gain insight into the potential words to add, we are going to calculate the TF-IDF, which is a combination of the term frequency and inverse document frequency. Essentially, we are going to punish terms that appear too frequently, such as articles, so that we can see which terms are more significant. To read more into this, read here: https://en.wikipedia.org/wiki/Tf%E2%80%93idf
To do this, we first have to calculate the IDF, which means we will have to represent each title as a bag of words, where each title will be represented as a vector of word frequencies. This is simple, as we already have the list of all words from our dataset as keys in our dictionary, 'freq'. Now we just have to iterate through each submission name and build a bag of words for each.
df = pd.DataFrame(columns = freq.keys())
valid_words = freq.keys()
# Create a index dictionary so we can quickly find which element corresponds to each word
ind_dict = dict()
for i,word in enumerate(freq.keys()):
ind_dict[word] = i
for title in titles:
# Create a list of size that matches how many terms we have. Init each to 0
row = [0] * len(freq.keys())
# If a word is found, increment its frequency
for word in nltk.word_tokenize(title):
if word.isalnum():
row[ind_dict[word]] = row[ind_dict[word]] + 1
df.loc[len(df)] = row
df
Now we can calculate the IDF! A term's IDF is equal to the log of the number of documents total divided by the number of documents that contain the term. A more visual example of this equation from a word 'j' is shown below. (Retrieved from CMSC 320 course slides)
 We will do this by counting the number of rows that are not equal to 0. You'll notice in the code below we just add boolean values, which is defined as either a 0 if False or 1 if True. Afterwards, we just apply the formula for each word.
We will do this by counting the number of rows that are not equal to 0. You'll notice in the code below we just add boolean values, which is defined as either a 0 if False or 1 if True. Afterwards, we just apply the formula for each word.
Finally, for each term let's calculate the TF-IDF by multiplying the term frequencies that we already calculated and the IDF we have just calculated. Each row in this resulting DataFrame will be our X, or input data, for fitting our logisitic regression
idf = dict()
# Calculate the IDF
num_docs = len(df)
for col in df.columns:
occurances = sum(df[col] != 0)
idf[col] = math.log(num_docs/occurances)
# Calculate the TF-IDF
for word in freq.keys():
df[word] = df[word] * idf[word]
df
I have manually went through the top 100 submissions in the 2020 dataset and manually labeled each submission as either 1 for "About US" or 0 for not "About US". Its important to note that this labeling inherently introduces bias.
As a disclaimer, when labeling titles, I typically labeled titles that dealt with US politics, current events, and international relations as "About US" and not submissions that dealt with US based companies, as I felt that these submissions were more broadly about economics than US politics.
y = [1,1,0,1,1,0,0,0,0,1,0,0,0,0,1,1,0,0,0,0,0,0,0,1,0,0,0,0,0,1,0,0,0,1,0,0,0,1,0,0,1,1,1,0,0,1,0,0,0,0,0,1,1,0,1,1,1,0,0,0,
0,0,0,0,0,1,0,1,0,0,0,0,1,0,0,0,1,0,1,0,0,0,0,0,1,0,0,0,0,1,0,0,0,0,0,0,0,1,1,0]
len(y)
Now we will convert our DataFrame to an array of numpy arrays, and pass it in with our y to fit a logisitic model. Afterwards, we will get the index locations of the highest coefficients and use them to receive the word that they correspond to. Using this, we will print out the 20 most important words when determining whether a submission title was about the US.
You can learn more about using a scikit's logistic regression at the following link:
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
# Convert DataFrame to appropriate format
X = df.to_numpy()
# Fit a logisitic regression
clf = LogisticRegression().fit(X,y)
# Get the coefficients, and get the 20 highest valued coefficients
coef = clf.coef_[0]
top_coef = nlargest(20, coef)
# Get the index locations of the highest values, which correspond to the words, which are the vcolumns of the dataframe
temp = list()
for ind in range(len(top_coef)):
val = top_coef[ind]
if not ind == 0 and top_coef[ind-1] == val:
temp = temp + np.where(coef == val)[0].tolist()
else:
temp = temp + np.where(coef == val)[0].tolist()
# The above method add duplicates to our list, we can easily just remove them
index_lst = list()
[index_lst.append(i) for i in temp if i not in index_lst]
# Finally print results
print('Top most influential words (in descending order):')
for i in index_lst:
print(df.columns[i])
Looking at our results, it would seem that "Trump" is the best indicator for whether a submission is about the US. This intuitively makes sense as Trump is the president of the United States, and thus there has been a lot of discussion about him and his actions. Unfortunately, many of the other words seem too general to include in our classifier. The word 'EU' comes up, while it could be conisdered the exact opposite of the US. Additionally, terms like 'military' make sense, but aren't specific to the US.
From this, it seems that the only word we can safely add to classifier is "Trump". However, we now have a process we can go through for any given dataset to receive the most important words for determining whether a title belongs to a specific class.
In addition to adding "Trump" to our terms, I feel it is only fair to also add 'Obama', who was the president from 2008 to 2016. The reason for this is because some of our dataset aligns with his term as President, and would make sense to have as an additional term for the US as he is a prominent US politician
Some More Exploratory Data Analysis
Finally, let's update our US classifier and use it to predict the proportion of posts that were about the US for every year in our dataset. This is a prediction since we are not completely sure of the accuracy of our classifier. We can pretty confidently assume that we will not have a false positive since checking whether a title contains a variant of the US or whether it discusses the current president will rarely ever not be about the US. However, we may miss submissions about current events that never explicitly mention it is in the US.
The proportion will be calculated as: the number of submissions marked as US / total number of submissions in the dataframe
Additionally, a post may be flaired to signify it is about the US. We can also use that to determine the subject of a submission.
us_terms = 'US|United States|U.S.|Trump|Obama'
prop_us = list()
curr_year = 2010
for df in df_lst:
# Ensure that flairs are interpretted as strings
df['flair'] = df['flair'].astype('string')
filter_lst_title = df['submission_name'].str.contains(us_terms).tolist()
filter_lst_flair = df['flair'].str.contains(us_terms, na='').tolist()
filter_lst = list()
for i in range(len(df)):
filter_lst.append(filter_lst_title[i] or filter_lst_flair[i])
prop_us.append([curr_year,len(df[filter_lst])/len(df)])
curr_year += 1
prop_us
For pure curiousity, I have ran the same code shown above excluding 'Obama' from the term list. The results are seen below. It would appear including him only marginally increases the percentages for 2010 to 2016.
We will still work with the proportions calculated from including his name, but it is an interesting fact to note that including him only marginally increases the proportions.
us_terms = 'US|United States|U.S.|Trump'
prop_us_trump = list()
curr_year = 2010
for df in df_lst:
# Ensure that flairs are interpretted as strings
df['flair'] = df['flair'].astype('string')
filter_lst_title = df['submission_name'].str.contains(us_terms).tolist()
filter_lst_flair = df['flair'].str.contains(us_terms, na='').tolist()
filter_lst = list()
for i in range(len(df)):
filter_lst.append(filter_lst_title[i] or filter_lst_flair[i])
prop_us_trump.append([curr_year,len(df[filter_lst])/len(df)])
curr_year += 1
prop_us_trump
Now let's see how much important Trump has been in topics related to the US. Let's see the how the proportions change when we remove Trump.
us_terms = 'US|United States|U.S.'
prop_us_no_trump = list()
curr_year = 2010
for df in df_lst:
# Ensure that flairs are interpretted as strings
df['flair'] = df['flair'].astype('string')
filter_lst_title = df['submission_name'].str.contains(us_terms).tolist()
filter_lst_flair = df['flair'].str.contains(us_terms, na='').tolist()
filter_lst = list()
for i in range(len(df)):
filter_lst.append(filter_lst_title[i] or filter_lst_flair[i])
prop_us_no_trump.append([curr_year,len(df[filter_lst])/len(df)])
curr_year += 1
prop_us_no_trump
Interestingly, and somewhat unsurprisingly, the proportion of posts for the years 2016 to 2020 dropped by about 15% when excluding Trump.
Linear Regression
Now for the final part of analysis, let's plot the proportions of posts about the US including Trump as a search term and excluding him as a search term.
# Resize the graphs
plt.rcParams["figure.figsize"] = [16,9]
# Plot the proportions, terms include both Trump and Obama
x,y = zip(*prop_us)
plt.scatter(x,y)
plt.title('Year vs. Proportion of submissions about US (All terms)')
plt.xlabel('Year')
plt.ylabel('Proportion of top 1000 posts about US')
# Make the y-axis the same scale so we don't draw incorrect conclusions by accident
x1, x2, y1, y2 = plt.axis()
plt.axis((x1, x2, 0, .5))
plt.show()
# Plot the proportions, terms exclude both Trump and Obama
x,y = zip(*prop_us_no_trump)
plt.scatter(x,y)
plt.title('Year vs. Proportion of submissions about US (No Trump, No Obama)')
plt.xlabel('Year')
plt.ylabel('Proportion of top 1000 posts about US')
# Make the y-axis the same scale so we don't draw incorrect conclusions by accident
x1, x2, y1, y2 = plt.axis()
plt.axis((x1, x2, 0, .5))
plt.show()


Looking at the scatterplots above, it appears that there may be a polynomial relationship for the plot of proportions when we use all terms, however there seems to be a linear relationship when excluding "Trump" and "Obama".
Let's plot a linear regression line for both to see the general trends, and let's plot a polynomial regression for the plot of proportions when we use all terms. To do this, we will simply transform the X to have the following pattern for each year:
[year, year^2, year^3]
We are using a 3rd degree polynomial as it seems like there is behavior before and after the year 2016 that should be modeled.
You can learn more about using scikit for linear regression at their API page:
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html
reg_all = LinearRegression()
reg_all_poly = LinearRegression()
reg_no_trump = LinearRegression()
year_lst = [2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020]
# The X data will be the same, and it will just be the years. The reshape is necessary to prepare data for fitting
X = np.array(year_lst).reshape(-1,1)
# Get the proportions to fit and then fit
y_all = [y[1] for y in prop_us]
reg_all.fit(X, y_all)
y_no_trump = [y[1] for y in prop_us_no_trump]
reg_no_trump.fit(X,y_no_trump)
# Polynomial Regression
X_poly = [[x, x**2, x**3] for x in year_lst]
reg_all_poly.fit(X_poly, y_all)
# Plot the proportions, terms include both Trump and Obama
x,y = zip(*prop_us)
plt.scatter(x,y)
plt.title('Year vs. Proportion of submissions about US (All terms)')
plt.xlabel('Year')
plt.plot(X, reg_all.predict(X), color = 'red')
plt.plot(X, reg_all_poly.predict(X_poly), color = 'red')
plt.ylabel('Proportion of top 1000 posts about US')
x1, x2, y1, y2 = plt.axis()
plt.axis((x1, x2, 0, .5))
plt.show()
# Plot the proportions, terms exclude both Trump and Obama
x,y = zip(*prop_us_no_trump)
plt.scatter(x,y)
plt.plot(X, reg_no_trump.predict(X), color = 'red')
plt.title('Year vs. Proportion of submissions about US (No Trump, No Obama)')
plt.xlabel('Year')
plt.ylabel('Proportion of top 1000 posts about US')
x1, x2, y1, y2 = plt.axis()
plt.axis((x1, x2, 0, .5))
plt.show()
print('Linear Regression for proportion using all terms:')
print('Coefficients:')
print(reg_all.coef_)
print('Intercept:')
print(reg_all.intercept_)
print('\nLinear Regression for proportion not using Trump or Obama:')
print('Coefficients:')
print(reg_no_trump.coef_)
print('Intercept:')
print(reg_no_trump.intercept_)


Looking at the above plot, we see that both scatterplots have a positive coefficient, meaning that the proportion of submissions about the US has slowly been growing. However, the magnitude of the coefficient changes depending on the term list used. When including Trump and Obama in our term list, the proportion of the top 1000 submissions being about the US grows by around 2.4% per year, however when we leave them off we only see a growth of .06% per year.
It is important to note that this is once again, an underestimate of the true proportion of submissions about the US, and by including more terms that we are sure we will not get false positives on (submissions we think are about the US but are not really), we will get closer to discovering the true proportion of submissions about the US.
Additionally, it is important to note that when including all terms, the proportion jumps from a steady 10% before 2016 to around 30% after 2016. Given the history of the US, I believe this can be most directly attributed to the election of Donald Trump to President of the United States. The proportions calculated when including and excluding "Trump" as a search term also support this.
Finally, I would like to point out the drop for year 2020 when looking at proportion using all terms. I believe this is not indicative of the US becoming less popular, but rather the problems of PushShift mentioned earlier. As the year is not over, and the data was collected close to November, there are many posts about the US election that should be apart of our dataset for 2020 but are not as PushShift has not updated their internal database yet.
Next, let's analyze our models using the R2 score.
all_r2_score = r2_score(y_all,reg_all.predict(X))
print('R2 Score for Linear Regression on Proportion using all terms:')
print(all_r2_score)
all_poly_r2_score = r2_score(y_all,reg_all_poly.predict(X_poly))
print('\nR2 Score for Polynomial Linear Regression on Proportion using all terms:')
print(all_poly_r2_score)
no_trump_r2_score = r2_score(y_no_trump,reg_no_trump.predict(X))
print('\nR2 Score for Linear Regression on Proportion without Trump or Obama used as terms:')
print(no_trump_r2_score)
Looking at the R2 scores, these results make sense. The R2 score ranges from 35% to 52%, which are good considering we are naively predicting the content of submissions over many years. It also makes sense that time is a good predictor, as these proportions will obviously change as time goes on, and different events happen.
Additionally, it makes sense that R2 score for the regression model that used all terms had a higher R2 score than the regression that did not use all terms, as using more terms would mean we gets a more accurate prediction of the true proportions of the submissions about the US.
Finally, it trivially makes sense why the Polynomial regression has the highest fit, as thats the whole point of the regression. By adding more degrees of freedom, we hope to further reduce error produced by a linear line. It is important to note that this often results in overfitting to the data presented, however this isn't a problem in our cases since we only used it to get a better idea of the trends that our data had.
Conclusions
So in conclusion, I believe we can include that the US has been more prevalent, at least on the worldnews reddit.
Looking at the regressions we just made, there has been a recent jump in the proportion of posts about the US from 2016 onwards, going from an average of 10% to about 30%. I believe this can most directly be attributed to the election of President Trump, as it aligns perfectly with the jump in the proportion from 10% to 30%. Additionally, it makes sense that Trump has caused a jump in popularity, as I have noticed, as an American, that he is involved in many controversial topics, both nationally and internationally. Finally, I would like to point out that this seems to be something that is more correlated with Trump as a person than his position as president. When getting the proportions using "Trump" and "Obama", there was only a slight increase when including "Obama" as a search term, but a huge drop when we removed "Trump" from the terms we were using to search.
Additionally, you may argue that the US making up to 30% of the top 1000 submissions a year is still not too significant, to which I argue that is not true. As said previously, our classifier picks up submissions that are explicitly about the US. As shown in our first exploratory data analysis section, while we were able to find about 40 posts about the protests in the US, only 10 of those were picked up by our US classifier. This shows that the proportion of submissions about the US is probably higher than what we predicted using our naive US classifier. The true proportion being higher than 30% for recent years could possibly near 50% depending on how many posts were misclassified as non-US. Given the context of a subreddit about international news, it is very significant if a single country makes up 50% of the top submissions in a given year.
Further Work
To take this project further, I believe my method of choosing terms about the US can be greatly expanded on given more resources. The dataset that I had to use to make the logistic regression to get the most important terms was extremely limited, and was further limited due to the fact that I had to manually label data. Given more data to draw from and more consideration with regards to how a submission title is labeled, I believe there will be interesting finds with regards to identifying the content of submissions from title alone.
Additionally, it may be worthwhile to look into new, different, and better ways to get Reddit data, as I ran into many issues trying to use PushShift, which is currently one of the best ways to get Reddit data.
Finally, it might be worth exploring if the same trend is also true for other international news subreddits aside from "worldnews".